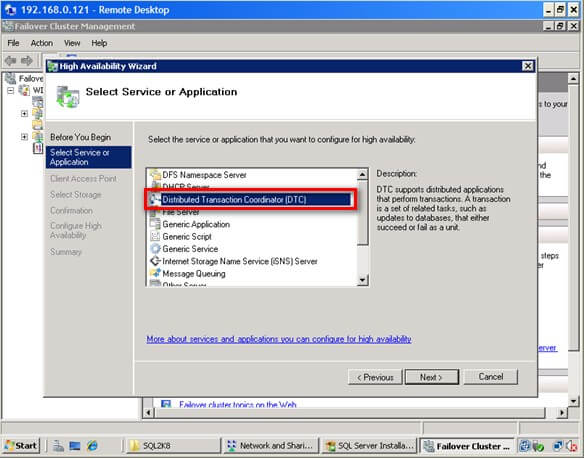
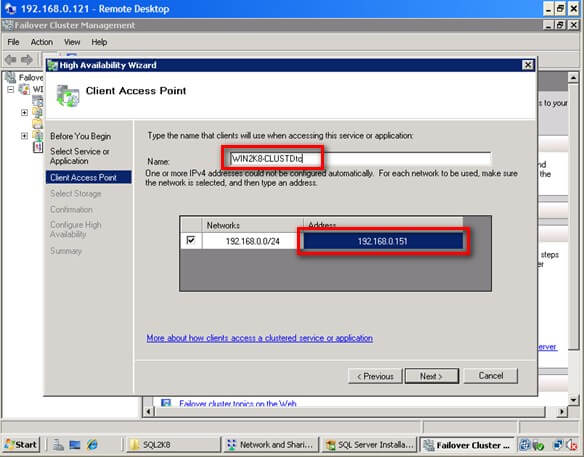
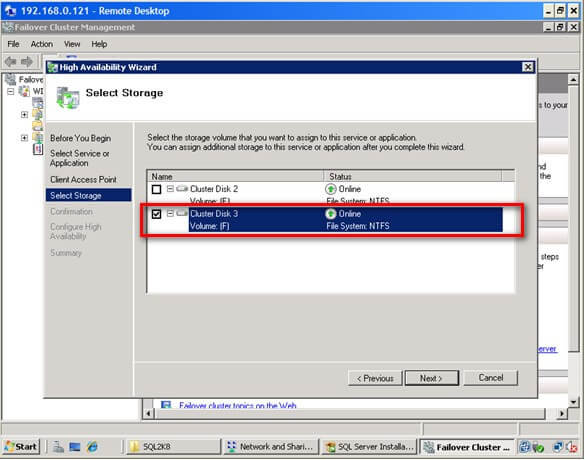
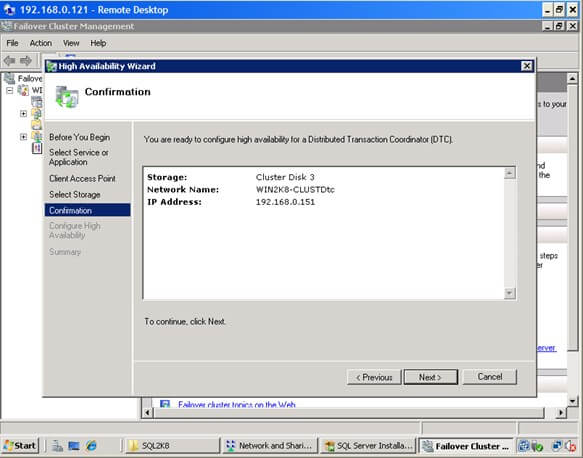
The following Microsoft SQL Server T-SQL functions are examples for scalar and table-valued UDF design:
1. dbo.fnSplitStringListXML -- applying xml xquery to split
2. dbo.fnSplitCSV -- applying charindex on number list
3. dbo.fnSplitCSVxml -- applying xml operations on number list
4. dbo.fnSplitStringList -- applying charindex on string list
5. dbo.fnNumberToEnglish -- translate number to words
6. dbo.tvfGetSalesInfoByProductColor -- like a view with parameter
7. dbo.fnSplitDelimitedStringList -- split delimited list
-- Split a comma-delimited string list with XML method
-- Table-valued user-defined function - TVF - SQL Server 2005/2008
-- Method uses XML xquery to split string list
CREATE FUNCTION dbo.fnSplitStringListXML (
@StringList VARCHAR(MAX),
@Delimiter CHAR(1))
RETURNS @TableList TABLE(ID int identity(1,1), StringLiteral VARCHAR(128))
BEGIN
IF @StringList = '' RETURN
IF @Delimiter = ''
BEGIN
WITH Split AS
( SELECT CharOne=LEFT(@StringList,1),R=RIGHT(@StringList,len(@StringList)-1)
UNION ALL
SELECT LEFT(R,1), R=RIGHT(R,len(R)-1)
FROM Split
WHERE LEN(R)>0 )
INSERT @TableList
SELECT CharOne FROM Split
OPTION ( MAXRECURSION 0)
RETURN
END -- IF
DECLARE @XML xml
SET @XML = '<root><csv>'+replace(@StringList,@Delimiter,'</csv><csv>')+
'</csv></root>'
INSERT @TableList
SELECT rtrim(ltrim(replace(Word.value('.','nvarchar(128)'),char(10),'')))
AS ListMember
FROM @XML.nodes('/root/csv') AS WordList(Word)
RETURN
END -- FUNCTION
GO
-- Test TVF
SELECT * FROM dbo.fnSplitStringListXML
('New York, California, Arizona, Texas, Toronto, Grand Canyon, Yosemite,
Yellow Stone, Niagara Falls, Belgium, Denmark, Hollandia, Sweden', ',')
/* ID StringLiteral
1 New York
2 California
3 Arizona
4 Texas
.... */
-- Test with empty string delimiter
SELECT * FROM dbo.fnSplitStringListXML ('9876543210','')
/* ID StringLiteral
1 9
2 8
3 7
.... */
-----------
-- Split comma-limited number list with the charindex function
-- Table-valued user-defined function - TVF
CREATE FUNCTION dbo.fnSplitCSV ( @NumberList varchar(4096))
RETURNS @SplitList TABLE ( ListMember INT )
AS
BEGIN
DECLARE @Pointer int, @ListMember varchar(25)
SET @NumberList = LTRIM(RTRIM(@NumberList))
IF (RIGHT(@NumberList, 1) != ',')
SET @NumberList=@NumberList+ ','
SET @Pointer = CHARINDEX(',', @NumberList, 1)
IF REPLACE(@NumberList, ',', '') <> ''
BEGIN
WHILE (@Pointer > 0)
BEGIN
SET @ListMember = LTRIM(RTRIM(LEFT(@NumberList, @Pointer - 1)))
IF (@ListMember <> '')
INSERT INTO @SplitList
VALUES (convert(int,@ListMember))
SET @NumberList = RIGHT(@NumberList, LEN(@NumberList) - @Pointer)
SET @Pointer = CHARINDEX(',', @NumberList, 1)
END
END
RETURN
END
GO
-- Test
SELECT * FROM dbo.fnSplitCSV ('')
SELECT * FROM dbo.fnSplitCSV ('1000')
SELECT * FROM dbo.fnSplitCSV ('1000,4005')
SELECT * FROM dbo.fnSplitCSV ('1000,7,9')
SELECT * FROM dbo.fnSplitCSV ('1000, 3, 8494, 2329992, 8, 23, 43')
GO
-- XML split solution for comma-limited number list
-- Table-valued user-defined function - TVF
CREATE FUNCTION dbo.fnSplitCSVxml
(@NumberList VARCHAR(4096))
RETURNS @SplitList TABLE( ListMember INT)
AS
BEGIN
DECLARE @xml XML
SET @NumberList = LTRIM(RTRIM(@NumberList))
IF LEN(@NumberList) = 0
RETURN
SET @xml = '' + REPLACE(@NumberList,',','') + ''
INSERT INTO @SplitList
SELECT x.i.value('.','VARCHAR(MAX)') AS Member
FROM @xml.nodes('//n') x(i)
RETURN
END
GO
-- Test
SELECT * FROM dbo.fnSplitCSVxml ('')
SELECT * FROM dbo.fnSplitCSVxml ('1000')
SELECT * FROM dbo.fnSplitCSVxml ('1000, 1007')
SELECT * FROM dbo.fnSplitCSVxml ('1000,7,9')
SELECT * FROM dbo.fnSplitCSVxml ('1000, 3, 8494, 2329992, 8, 23, 43')
GO
-- Split a comma-delimited string list
-- Table-valued user-defined function - TVF
CREATE FUNCTION dbo.fnSplitStringList (@StringList VARCHAR(MAX))
RETURNS @TableList TABLE( StringLiteral VARCHAR(128))
BEGIN
DECLARE @StartPointer INT, @EndPointer INT
SELECT @StartPointer = 1, @EndPointer = CHARINDEX(',', @StringList)
WHILE (@StartPointer < LEN(@StringList) + 1)
BEGIN
IF @EndPointer = 0
SET @EndPointer = LEN(@StringList) + 1
INSERT INTO @TableList (StringLiteral)
VALUES(LTRIM(RTRIM(SUBSTRING(@StringList, @StartPointer,
@EndPointer - @StartPointer))))
SET @StartPointer = @EndPointer + 1
SET @EndPointer = CHARINDEX(',', @StringList, @StartPointer)
END -- WHILE
RETURN
END -- FUNCTION
GO
-- Test
SELECT * FROM dbo.fnSplitStringList ('New York, California, Arizona, Texas')
GO
SELECT * FROM dbo.fnSplitStringList ('New York, California, Arizona, Texas,')
GO
SELECT * FROM dbo.fnSplitStringList ('New York')
SELECT * FROM dbo.fnSplitStringList ('Smith, Brown, O''Brien, Sinatra')
GO
------------
-- Translate an integer number into English words
-- T-SQL convert number to English words - scalar-valued function
USE AdventureWorks2008;
GO
CREATE FUNCTION dbo.fnNumberToEnglish (@Number INT)
RETURNS VARCHAR(1024)
AS
BEGIN
DECLARE @Below20 TABLE( ID INT IDENTITY ( 0 , 1 ),
Word VARCHAR(32) )
DECLARE @Tens TABLE( ID INT IDENTITY ( 2 , 1 ),
Word VARCHAR(32) )
INSERT @Below20 (Word)
VALUES('Zero'),
('One'),
('Two'),
('Three'),
('Four'),
('Five'),
('Six'),
('Seven'),
('Eight'),
('Nine'),
('Ten'),
('Eleven'),
('Twelve'),
('Thirteen'),
('Fourteen'),
('Fifteen'),
('Sixteen'),
('Seventeen'),
('Eighteen'),
('Nineteen')
INSERT @Tens VALUES('Twenty'),
('Thirty'),
('Forty'),
('Fifty'),
('Sixty'),
('Seventy'),
('Eighty'),
('Ninety')
DECLARE @English VARCHAR(1024) = (SELECT CASE
WHEN @Number = 0 THEN ''
WHEN @Number BETWEEN 1 AND 19 THEN
(SELECT Word
FROM @Below20
WHERE ID = @Number)
WHEN @Number BETWEEN 20 AND 99 THEN
(SELECT Word
FROM @Tens
WHERE ID = @Number / 10) + '-' + dbo.fnNumberToEnglish(@Number%10)
WHEN @Number BETWEEN 100 AND 999 THEN (dbo.fnNumberToEnglish(@Number / 100))
+ ' Hundred ' + dbo.fnNumberToEnglish(@Number%100)
WHEN @Number BETWEEN 1000 AND 999999
THEN (dbo.fnNumberToEnglish(@Number / 1000)) + ' Thousand '
+ dbo.fnNumberToEnglish(@Number%1000)
ELSE ' INVALID INPUT' END)
SELECT @English = RTRIM(@English)
SELECT @English = RTRIM(LEFT(@English,len(@English) - 1))
WHERE RIGHT(@English,1) = '-'
RETURN (@English)
END
GO
-- Test numeric-to-words UDF
SELECT NumberInEnglish=[dbo].[fnNumberToEnglish]( 999 )
-- Nine Hundred Ninety-Nine
SELECT NumberInEnglish=[dbo].[fnNumberToEnglish]( 15888 )
-- Fifteen Thousand Eight Hundred Eighty-Eight
SELECT NumberInEnglish=[dbo].[fnNumberToEnglish]
( CONVERT(INT,CONVERT(MONEY,'$120,453')))
-- One Hundred Twenty Thousand Four Hundred Fifty-Three
GO
------------
-- TVF and inline TVF like a view with parameter
-- SQL create table-valued function like a parametrized view
CREATE FUNCTION dbo.tvfGetSalesInfoByProductColor
(@Color NVARCHAR(16))
RETURNS @retSalesInformation TABLE(-- Columns returned by the function
ProductName NVARCHAR(50) NULL,
NonDiscountSales MONEY,
DiscountSales MONEY,
Color NVARCHAR(16) NULL)
AS
BEGIN
INSERT @retSalesInformation
SELECT p.Name,
SUM(OrderQty * UnitPrice),
SUM((OrderQty * UnitPrice) * UnitPriceDiscount),
@Color
FROM Production.Product p
INNER JOIN Sales.SalesOrderDetail sod
ON p.ProductID = sod.ProductID
WHERE Color = @Color
OR @Color IS NULL
GROUP BY p.Name
RETURN;
END;
GO
-- Using a TVF like a table
SELECT * FROM dbo.tvfGetSalesInfoByProductColor ('Yellow') ORDER BY ProductName
-- (34 row(s) affected)
/*
ProductName NonDiscountSales DiscountSales Color
HL Touring Frame - Yellow, 46 52404.102 0.00 Yellow
HL Touring Frame - Yellow, 50 49994.718 0.00 Yellow
HL Touring Frame - Yellow, 54 324001.9134 733.6575 Yellow
…
*/
SELECT * FROM dbo.tvfGetSalesInfoByProductColor ('') ORDER BY ProductName
-- (0 row(s) affected)
SELECT * FROM dbo.tvfGetSalesInfoByProductColor (NULL) ORDER BY ProductName
-- (266 row(s) affected)
GO
------------
-- SQL create INLINE table-valued function like a parametrized view
CREATE FUNCTION dbo.itvfGetSalesInfoByColor
(@Color NVARCHAR(16))
RETURNS TABLE
AS
RETURN (
SELECT ProductName = p.Name,
NonDiscountSales = SUM(OrderQty * UnitPrice),
DiscountSales = SUM((OrderQty * UnitPrice) * UnitPriceDiscount),
Color = @Color
FROM Production.Product p
INNER JOIN Sales.SalesOrderDetail sod
ON p.ProductID = sod.ProductID
WHERE Color = @Color
OR @Color IS NULL
GROUP BY p.Name );
GO
-- Using an ITVF like a table
SELECT * FROM dbo.itvfGetSalesInfoByColor ('Yellow') ORDER BY ProductName
-- (34 row(s) affected)
/*
ProductName NonDiscountSales DiscountSales Color
HL Touring Frame - Yellow, 46 52404.102 0.00 Yellow
HL Touring Frame - Yellow, 50 49994.718 0.00 Yellow
HL Touring Frame - Yellow, 54 324001.9134 733.6575 Yellow
*/
SELECT * FROM dbo.itvfGetSalesInfoByColor ('') ORDER BY ProductName
-- (0 row(s) affected)
SELECT * FROM dbo.itvfGetSalesInfoByColor (NULL) ORDER BY ProductName
-- (266 row(s) affected)
GO
------------
-- Split delimited string
CREATE FUNCTION dbo.fnSplitDelimitedStringList
(@StringList NVARCHAR(MAX),
@Delimiter NVARCHAR(5))
RETURNS @TableList TABLE(ID INT IDENTITY(1,1), StringLiteral NVARCHAR(1024))
BEGIN
DECLARE @StartPointer INT,
@EndPointer INT
SELECT @StartPointer = 1,
@EndPointer = CHARINDEX(@Delimiter,@StringList)
WHILE (@StartPointer < LEN(@StringList) + 1)
BEGIN
IF @EndPointer = 0
SET @EndPointer = LEN(@StringList) + 1
INSERT INTO @TableList
(StringLiteral)
VALUES (LTRIM(RTRIM(SUBSTRING(@StringList,@StartPointer,
@EndPointer - @StartPointer))))
SET @StartPointer = @EndPointer + 1
SET @EndPointer = CHARINDEX(@Delimiter,@StringList,@StartPointer)
END -- WHILE
RETURN
END -- FUNCTION
GO
SELECT * FROM fnSplitDelimitedStringList ('New York; New Jersey; Texas', ';')
/* ID StringLiteral
1 New York
2 New Jersey
3 Texas
*/
------------